This is the first of two weeks of analyze type work. Although this week's effort mostly focused on analyzing how the data would be presented in a few weeks. This was accomplished by utilizing web mapping tools and applications, which is built around presenting maps to the public in an open sourced manner. This week we are transforming some of the prep work created last week into the web forum in preparation of distributing it to the masses. The overall objectives this week are as followed:
1. Navigate through, and add layers to Tilemill
2. Gain familiarity with Leaflet
3. Use tiled layers and plug-ins in a web map
The main theme to all of the above objectives before looking at them individually is that they are open source! That means anyone has the ability to acquire them, learn about them, and in most cases contribute to the community with them.
Tilemill is an interactive mapping software predominately used by cartographers and journalists to create interactive maps for sharing with the public. Leaflet is a javascripting utility which allows you to code html web maps for display, much like the one linked below. The layer tiling mentioned in the last objective was accomplished with some basic html code using Notepad, and shared on a webmapping host.
The Web Map I created displays the end result of this week's efforts. It combines the objectives mentioned above with the data we looked at last week for food deserts in the Pensacola, FL area. Every feature or option on this map falls into one of the objectives above. However, after thoroughly reading through the instructions numerous times, ensuring I didn't skip a step, I was unable to get the tiled layer function to work properly. My legend is visible, however, there is not an option to turn on or off the layers. I think there may have been a step missing from the instructions. Nevertheless, I was able to get the find function to appear in the lower left. The points, polygons, and circle are also very specific. Each of these elements is an individual block or segment of code which was pre-thought out to contribute to the map in this specific manner. This was all done to get familiar with these applications and get ready to present my own specific area exploring food deserts in a couple weeks.
Saturday, November 26, 2016
Friday, November 18, 2016
GIS 4930: Special Topics; Project 4 - Open Source Prep
Welcome to the beginning of the last multi-week module in Special Topics in GIS. The focus for the remainder of the class is on Food Deserts and their increasing proliferation due to urbanization and expansion of the markets/grocers containing wholesome and nutritious foods to include fresh vegetables and fruits as well as other produce. The second large aspect of this project is that all preparation, analysis, and reporting for the focus area will be done using open source software. As the certificate program as a whole draws to a close, it is a good introduction into what is available outside of ESRI's ArcGIS suite of applications. This week I specifically used Quantum GIS (QGIS) to build the base map and do the initial processing of Food Desert data for the Pensacola area of Escambia County, Florida. The overall objectives going into this week are listed below:
1. Perform basic navigation through QGIS
2. Learn about the differences of data processing with multiple data sets and geoprocessing tools in QGIS, while employing multiple data frames and similar functionality.
3. Experience the differences of map creation with the QGIS specific Print Composer
Below is a map not unlike many of the others I have created using ArcMap. That is, in fact, the point of one huge aspect of this project. There is open source, defined as free to use software which you can personally suggest improvements for update and redistribution to the masses. These open source applications perform quite similar tasks and produce similar outputs as those in ArcMap. QGIS is one of these options. Given the background in ArcGIS from the rest of this certificate program, there is not a steep learning curve in picking up QGIS and running with it. There are definitely differences, but with little instruction it becomes very intuitive just like ArcMap. Now you might be wondering, if these two softwares are so similar, then why wouldn't everyone choose QGIS over any ESRI related products? There are still advanced tools and spatial analysis functions in ArcGIS that are beyond this software. For the basic to moderate tasks, they can definitely be done in QGIS. But sometimes there will be no substitute for the processing ease and power of ArcGIS.
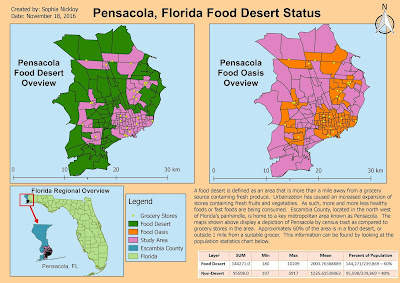
Back to the map provided, what you're looking at is two frames, or two sides of the same information. You are presented with both Food Deserts and Food Oasis by census tract for the Pensacola area of Escambia County. These deserts were calculated by comparing the centroid (geographic center) of a census tract with its distance to a grocery store. Tracts without a grocery store providing fresh produce are said to be in a Food Desert. The average person in these areas have to travel further to obtain fruits and vegetables. When doing so, other closer, less healthy alternatives might be taking precedence for these people. Ultimately, those with less access are likely to be less healthy overall and that is the issue we are starting to get into with this subject.
Keep checking for the next installments of analysis as we continue to look at this issue. The area shown below is just for example purposes. As the project moves forward, my analysis and results will focus on Rockledge, Florida, which is located in Brevard County.
1. Perform basic navigation through QGIS
2. Learn about the differences of data processing with multiple data sets and geoprocessing tools in QGIS, while employing multiple data frames and similar functionality.
3. Experience the differences of map creation with the QGIS specific Print Composer
Below is a map not unlike many of the others I have created using ArcMap. That is, in fact, the point of one huge aspect of this project. There is open source, defined as free to use software which you can personally suggest improvements for update and redistribution to the masses. These open source applications perform quite similar tasks and produce similar outputs as those in ArcMap. QGIS is one of these options. Given the background in ArcGIS from the rest of this certificate program, there is not a steep learning curve in picking up QGIS and running with it. There are definitely differences, but with little instruction it becomes very intuitive just like ArcMap. Now you might be wondering, if these two softwares are so similar, then why wouldn't everyone choose QGIS over any ESRI related products? There are still advanced tools and spatial analysis functions in ArcGIS that are beyond this software. For the basic to moderate tasks, they can definitely be done in QGIS. But sometimes there will be no substitute for the processing ease and power of ArcGIS.
Back to the map provided, what you're looking at is two frames, or two sides of the same information. You are presented with both Food Deserts and Food Oasis by census tract for the Pensacola area of Escambia County. These deserts were calculated by comparing the centroid (geographic center) of a census tract with its distance to a grocery store. Tracts without a grocery store providing fresh produce are said to be in a Food Desert. The average person in these areas have to travel further to obtain fruits and vegetables. When doing so, other closer, less healthy alternatives might be taking precedence for these people. Ultimately, those with less access are likely to be less healthy overall and that is the issue we are starting to get into with this subject.
Keep checking for the next installments of analysis as we continue to look at this issue. The area shown below is just for example purposes. As the project moves forward, my analysis and results will focus on Rockledge, Florida, which is located in Brevard County.

Tuesday, November 8, 2016
GIS 4035: Remote Sensing; Week 10: Supervised Image Classification
This week's focus was on supervised classification, particularly with the Maximum Likelihood method. This is a continuation of last week that started the classification discussion with unsupervised classification.
Supervised classification revolves around the creation of training sites to train the software in what to look for when conducting the classification. This is accomplished by creating a polygon type area of spectrally similar pixels. Examples would be dense forest, grassland, or water. Each area has a distinct spectral signature. These signatures are used to evaluate the whole of the image and allow the software to automatically reclassify all matching spectral areas. The overall process is usually in four steps: get your image, establish spectral signatures, run the classification based on the signatures, then reclassify or identify rather what your class schema is.
The process is fairly straightforward with only a couple things to watch out for when establishing the spectral signatures. Being sure to avoid spectral confusion. This is where multiple features exhibit similar spectral signatures. This usually occurs most frequently in the visual bands, and can be avoided by doing a good check using tools such as band histograms or spectral mean plotting which shows you the mean spectral value of one or more bands simultaneously. We can see some of the results of this below, such as the merging of the urban/residential and the roads/urban mix.
The image below shows a Land Use derivative for Germantown, Maryland. It was created using a base image and supervised classification looking for the categories displayed in the legend. This map shows the acreage of areas as they currently exist and is intended to provide a baseline for change. As areas get developed, the same techniques can be used on more and more current imagery to map the change and gauge which land uses are expanding/shrinking most and by how much. This was an excellent introduction to one method of supervised classification, there are many types and reasons to conduct it, but those are for another class.

Supervised classification revolves around the creation of training sites to train the software in what to look for when conducting the classification. This is accomplished by creating a polygon type area of spectrally similar pixels. Examples would be dense forest, grassland, or water. Each area has a distinct spectral signature. These signatures are used to evaluate the whole of the image and allow the software to automatically reclassify all matching spectral areas. The overall process is usually in four steps: get your image, establish spectral signatures, run the classification based on the signatures, then reclassify or identify rather what your class schema is.
The process is fairly straightforward with only a couple things to watch out for when establishing the spectral signatures. Being sure to avoid spectral confusion. This is where multiple features exhibit similar spectral signatures. This usually occurs most frequently in the visual bands, and can be avoided by doing a good check using tools such as band histograms or spectral mean plotting which shows you the mean spectral value of one or more bands simultaneously. We can see some of the results of this below, such as the merging of the urban/residential and the roads/urban mix.
The image below shows a Land Use derivative for Germantown, Maryland. It was created using a base image and supervised classification looking for the categories displayed in the legend. This map shows the acreage of areas as they currently exist and is intended to provide a baseline for change. As areas get developed, the same techniques can be used on more and more current imagery to map the change and gauge which land uses are expanding/shrinking most and by how much. This was an excellent introduction to one method of supervised classification, there are many types and reasons to conduct it, but those are for another class.

Sunday, November 6, 2016
GIS 4930: Special Topics; Project 3: Stats Analyze Week
Welcome to the continuation of our look at statistical analysis with ArcMap. Recall that the theme being explored with statistics is methamphetamine lab busts around Charleston, West Virginia. These past few weeks of analysis have been the bulk of the work for this project. The overall objectives of the analysis portion are to review and understand regression analysis basics, and a couple key techniques. Define what the dependent and independent variables are for the study as they apply to the regression analysis. Perform (multiple renditions) of an Ordinary Least Squares (OLS) regression model. Finally, complete 6 statistical sanity checks based on the OLS model outcomes.
In the previous post, we looked at a big overview of the area that is being analyzed. There are 54 lab busts from the 2004-2008 time frame taken from the DEA's National Clandestine Laboratory data. Decennial census data from 2000 and 2010 at the census tract level was spatially joined to these 54 lab busts. The data was then normalized into a percentage by the census tract into 31 categories for analysis in the OLD model. These 31 categories of data were then fed into the model and systematically removed while analyzing their affect on the model. Ultimately as good of a model as possible was arrived at with some results shown below.

This is a generated output depicting the OLS results created in ArcMap. Key things to note from the table is that there are only nine variables being incorporated into the OLS model of the original 31. How were variables removed you might ask? There are six checks, or questions, to answer to determine the validity of a variable's use in the OLS model: does an independent variable help or hurt the model; is the relationship to the dependent variable as expected; are there redundant explanatory variables; is the model biased; are there variables missing or unexplained residuals; how well does the model predict the dependent variable? The first three of these were generally grouped into one solid check for determining if a variable should stay or go. The remaining checks were applied to the model results as a whole. As long as a variable had a coefficient that wasn't near zero, a probability lower than 0.4, and a VIF less than 7.5, it could stay. After looking at this data table, it's time to transition to the visual interpretation, shown below.

In the previous post, we looked at a big overview of the area that is being analyzed. There are 54 lab busts from the 2004-2008 time frame taken from the DEA's National Clandestine Laboratory data. Decennial census data from 2000 and 2010 at the census tract level was spatially joined to these 54 lab busts. The data was then normalized into a percentage by the census tract into 31 categories for analysis in the OLD model. These 31 categories of data were then fed into the model and systematically removed while analyzing their affect on the model. Ultimately as good of a model as possible was arrived at with some results shown below.

This is a generated output depicting the OLS results created in ArcMap. Key things to note from the table is that there are only nine variables being incorporated into the OLS model of the original 31. How were variables removed you might ask? There are six checks, or questions, to answer to determine the validity of a variable's use in the OLS model: does an independent variable help or hurt the model; is the relationship to the dependent variable as expected; are there redundant explanatory variables; is the model biased; are there variables missing or unexplained residuals; how well does the model predict the dependent variable? The first three of these were generally grouped into one solid check for determining if a variable should stay or go. The remaining checks were applied to the model results as a whole. As long as a variable had a coefficient that wasn't near zero, a probability lower than 0.4, and a VIF less than 7.5, it could stay. After looking at this data table, it's time to transition to the visual interpretation, shown below.

This map depicts the standard residual for the OLS model depicted in the table. It symbolizes areas using a standard deviation style outlook. However, rather than wanting a more Gaussian curve style of data showing some of every color, you ideally want values to be in the +/- 0.5 range because that is said to be highly accurate. Darker browns indicate areas that the model predicted less meth labs actually were. Whereas, darker blues indicate high value areas where the model expected more meth labs than those that were actually present.
This week's focus was not to describe the data results, but to accomplish the analysis leading up to it..
Tuesday, November 1, 2016
GIS 4035: Remote Sensing; Module 9: Unsupervised Classification
This week's assignment revolved around unsupervised classification with remotely sensed imagery. This is a multifaceted lab looking at a number of different processes culminating in the unsupervised classification and manual reclassifying of the resulting raster dataset for a permeability analysis. The main objective was to understand and perform an unsupervised classification in both ArcMap and ERDAS Imagine. Imagery for two different areas was provided, ultimately the UWF area, as seen in the map below, was the final subject matter for exploration of these topics.
Unsupervised classification is a classification method such that a software suite utilizes an algorithm to determine which pixels in the raster image are most like other pixels throughout the image and groups them accordingly. After the software has grouped the various pixels together, it is up to the user to define what the group classes represent. For this type of classification, the software is given certain user defined parameters such as number of iterations to run, confidence or threshold percentage to reach, and sample sizes. These essentially tell the software how long to run, what the minimum "correctly grouped" pixel percentage is, and how many pixels to look at adjusting at a time.
A high definition true color image of the UWF campus was used for the analysis shown below. This entailed performing a clustering algorithm on the true color image to group like pixels together and then export them as a slightly less defined image for storage space and processing speed concerns. The clustering algorithm created 50 classes, or shades of pixels which approximated the true color image. The software was told to produce 50 classes with 95% accuracy overall. Then I manually reclassified each of those 50 original classes into one of 5 labeled classes. I accomplished this by highlighting the pixel shade and reviewing it against the true color image and assigning it to the classes described. Four of the five classes are straightforward and represent what they say, with some possible error. The mixed class, however, represents certain pixel shades applied to different items that represent both permeable or impermeable surfaces. For example, some dead grass showing could show a tan pixel while a tan rooftop could also be showing the same value. So recoding this pixel to be grass or buildings would be wrong for at least some of that cluster of pixels. To account for this the mixed class was created, which is why you can see some rooftops as blue, grassy areas as blue or green and some blue sprinkled throughout.
Overall, this is a fairly course analysis, but it does do a great job of exercising the process and creating likely results.

Unsupervised classification is a classification method such that a software suite utilizes an algorithm to determine which pixels in the raster image are most like other pixels throughout the image and groups them accordingly. After the software has grouped the various pixels together, it is up to the user to define what the group classes represent. For this type of classification, the software is given certain user defined parameters such as number of iterations to run, confidence or threshold percentage to reach, and sample sizes. These essentially tell the software how long to run, what the minimum "correctly grouped" pixel percentage is, and how many pixels to look at adjusting at a time.
A high definition true color image of the UWF campus was used for the analysis shown below. This entailed performing a clustering algorithm on the true color image to group like pixels together and then export them as a slightly less defined image for storage space and processing speed concerns. The clustering algorithm created 50 classes, or shades of pixels which approximated the true color image. The software was told to produce 50 classes with 95% accuracy overall. Then I manually reclassified each of those 50 original classes into one of 5 labeled classes. I accomplished this by highlighting the pixel shade and reviewing it against the true color image and assigning it to the classes described. Four of the five classes are straightforward and represent what they say, with some possible error. The mixed class, however, represents certain pixel shades applied to different items that represent both permeable or impermeable surfaces. For example, some dead grass showing could show a tan pixel while a tan rooftop could also be showing the same value. So recoding this pixel to be grass or buildings would be wrong for at least some of that cluster of pixels. To account for this the mixed class was created, which is why you can see some rooftops as blue, grassy areas as blue or green and some blue sprinkled throughout.
Overall, this is a fairly course analysis, but it does do a great job of exercising the process and creating likely results.

Subscribe to:
Comments (Atom)